

Luna Tech | Regular Express Tutorial for Everyone

1. Why this tutorial
Hi everyone, this is my second technical English tutorial, and I decided to write a post about Regex (short for Regular Expression).
The reason being that, I have tried multiple times to read different tutorials on Regex, but I never succeeded to finish any of them.
There’re just tooooo many different symbols to learn, and to be honest, I easily lost my patience reading those tutorials.
Last week, I took a LinkedIn online course (https://www.lynda.com/Regular-Expressions-tutorials/Learning-Regular-Expressions/2819183-2.html) about Regex, which is a lifesaver to me, because the author illustrates everything so clearly.
After completing this course, I’m able to read and write Regex to serve my own objective, and the main reason is that, I understand the basics and how the Regex engine works.
Today, I’ll try to explain the key points to you, and hopefully, someone will get value from this post.
Let’s get started!
Note: For a better reading experience, please open this link in a computer browser, the mobile view really messed up the formatting, especially the tables.
2. Beginner’s common questions
1. What is Regex and why we need to learn it?
From my point of view, Regex is essentially a tool for matching patterns and ultimately, improve the search efficiency.
Imagine you are working with a text file, and you need to find all the “interest”, “interesting”, “interested” occurrence in the file.
With the normal search function, you cannot search for these three words at the same time, you need to do 3 different queries to find what you want.
1. Search “interest”
2. Search “interesting”
3. Search “interested”
But with Regex, you can use only one query to find all the words you want, just use the expression below:
/interest[ie]*[nd]*g*/g
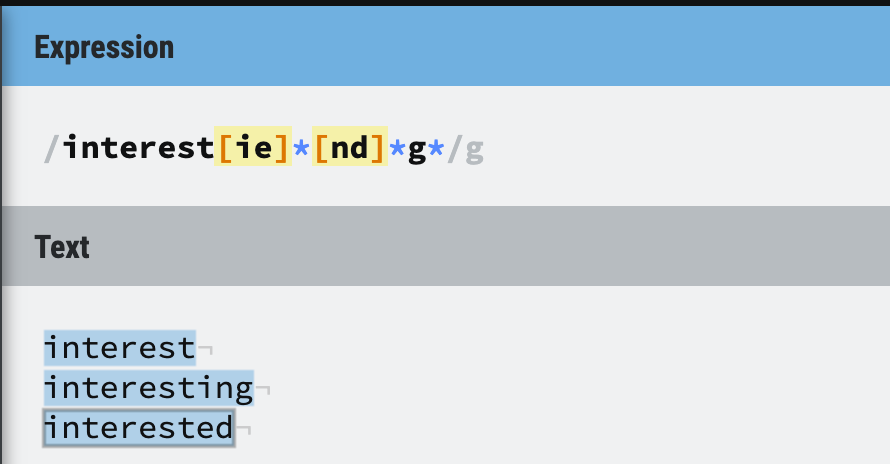
Figure 1: Regex makes life easier
From this simple example, you can see how Regex can make our life easier because it does the pattern matching job. It is a very powerful tool for matching, searching and replacing text, because you can specify the string length, whether it can appear in multiple lines and so on.
Another common use case of Regex is to validate user input, for example, no special character is allowed, only digits are allowed, whether it is a valid email address, etc.
What is regexp?
Regex and Regexp are both short for Regular Expression, so they are the same.
2. Is Regex a programming language?
The answer is no.
It is just a special text string, and is used by programming languages to process string values.
How can programming language recognize Regex?
Regex is usually wrapped in //, but different programming languages may use different Regular Expression Engines.
The main job of the Regex engine is to find the matches for your expression. Most Regex engines work similarly, so what we are learning here applies to them in most cases.
3. Basic Regex Knowledge
In the next part, we’re going to use an online tool to learn, write and test regular expressions, before actually doing that, we need to have some basic knowledge about Regex.
Regex learning tool: https://regexr.com/
Regex Flags and Regex Engine
First, let’s take a look at the top right part of the website.
There’re 2 different Regex Engines that we can choose (JavaScript and PCRE), and each Regex engine has 6 different Flags that we can tick on or off.
I am not going to explain all the flags, but
globalandmultilineare covered in this tutorial.
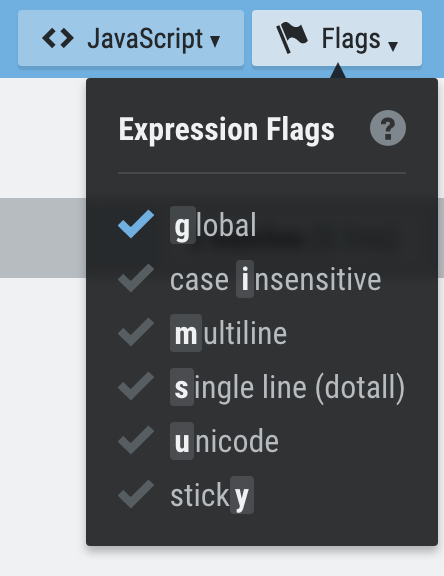
Figure 2: JavaScript Regex Engine
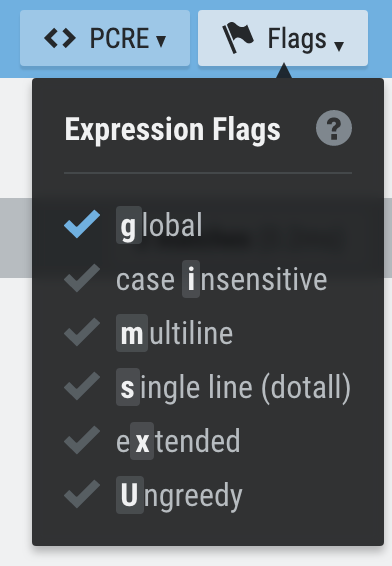
Figure 3: PCRE Regex Engine
Regex Flags
1. /expression/g -> search all the matches
2. /expression/i -> search all the matches regardless of uppercase or lowercase
3. /expression/m -> search all the matches
For now, we are going to use JavaScript Engine with the global flag ticked, ticking on the global flag means we want to find all the matches in the text, not just the first match.
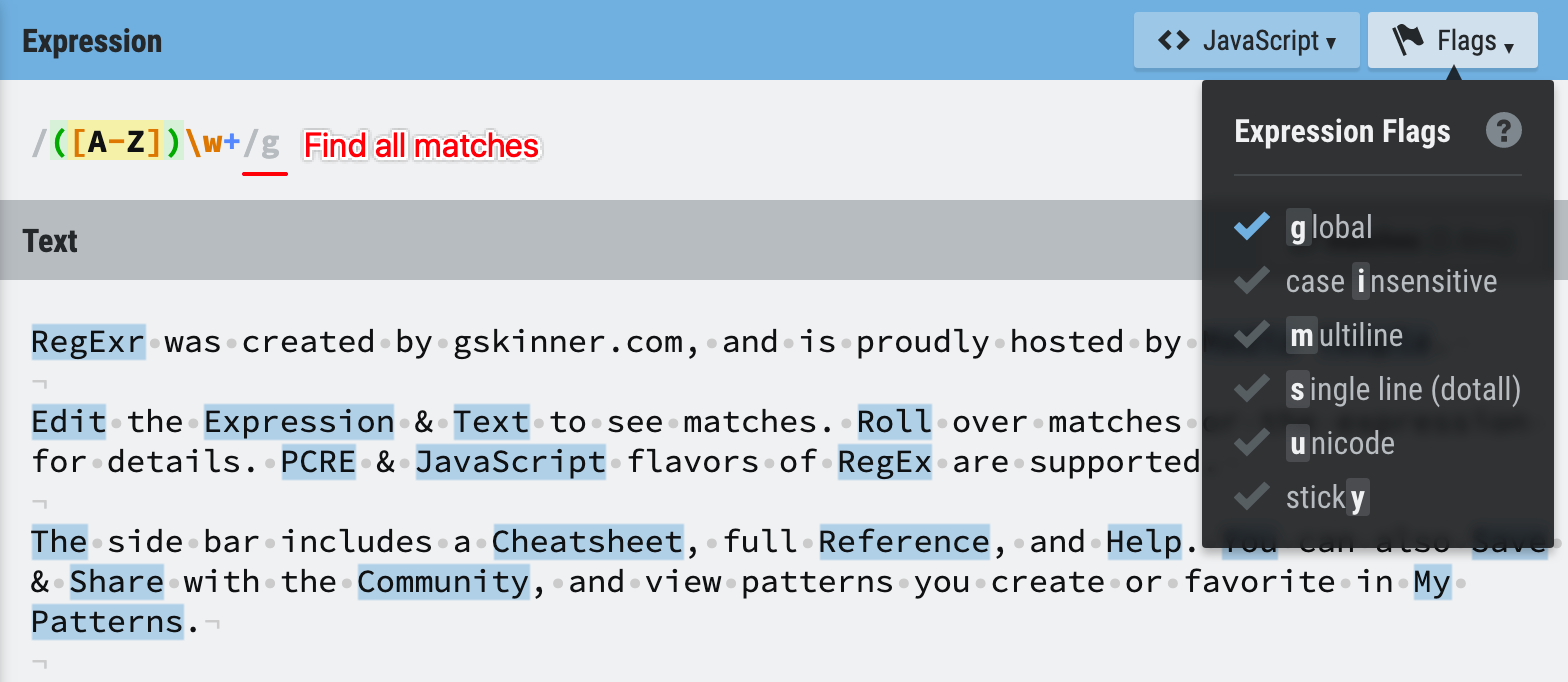
Figure 4: Global flag on
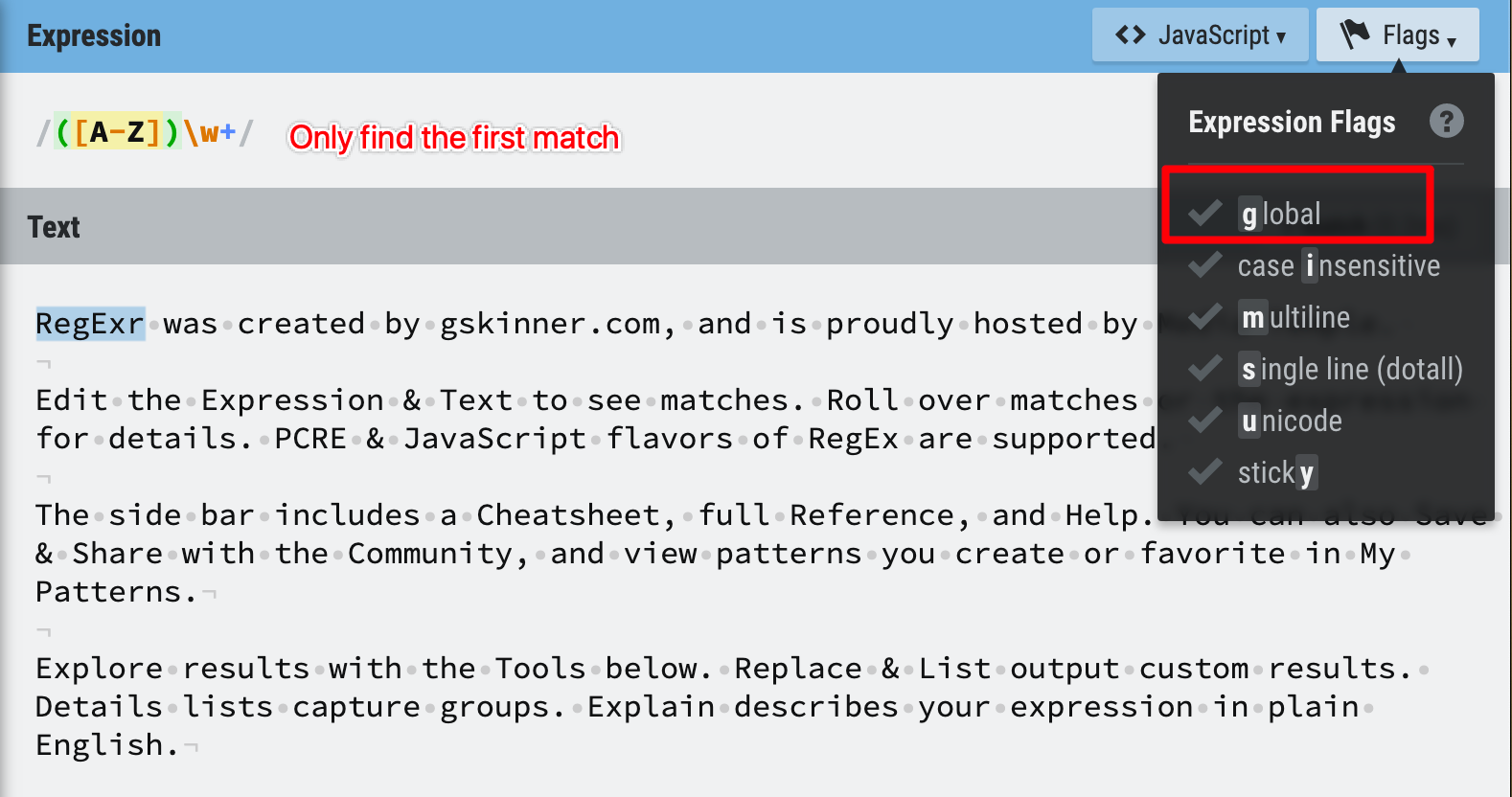
Figure 5: Global flag off
Three types of Characters
There are two types of characters in Regex: Literal Characters, Metacharacters and Special Characters.
Most characters that we can type on the keyboard are Literal Characters, only a few of them are given special meanings for the Regex engine to do pattern matching, those special characters are called metacharacters.
Below is a table of metacharacter and their meanings, you don’t need to worry about memorizing it, you just need to know this is a table for your reference, you can refer to it whenever you need it.
Advice: Just have a glance at it and move to the next part! Don’t try to memorize them!
| Metacharacter | Meaning |
|---|---|
/ |
The start/end of the regex e.g., /pattern/ |
\ |
Escape from special meaning e.g., /0\.9/ |
. |
Wildcard metacharacter, matches any character except newline e.g., /0.9/ |
* |
item before appear 0 or more times e.g., /a*/ |
+ |
item before appear 1 or more times e.g., /a+/ |
? |
item before appear 0 or 1 time e.g., /a?/ |
- |
Defines a character range e.g., /[0-9]/ |
pipe |
Alternation (OR) |
{ } |
Quantified Repetition e.g., /a{3,5}/ |
[ ] |
Defines a Character Set e.g., /[aeiou]/ |
( ) |
Defines a group e.g., /(group1)-(group2)/ |
^ |
1. When used at the start of a character set, defines a negative set. e.g., /[^aeiou]/2. When used at the start of Regex, means the start of string/line. e.g., /^Banana/ |
$ |
End of string/line e.g., /Banana$/ |
\A |
Start of string, not end of line e.g., /\ABanana/JS engine not support |
\Z |
End of string, not end of line e.g., /Banana\Z/JS engine not support |
\b |
Word boundary (start/end of a word) e.g., /\bApple\b/ |
\B |
Not a word boundary e.g., /\Bea\B/ |
Note:
|cannot be correctly rendered in the markdown table above, so I usepipefor alternation.e.g.,
/match1|match2|match3)/
What does metacharacter mean?
1. This character will be interpreted by the Regex Engine with special meaning
2. So if you literally want to find the ^ character inside a string, you need to use \^ to escape from the special meaning and turn it into a literal character.
3. And if you want to escape the escape metacharacter(\), you just need to use \\.
4. One metacharacter can have more than one meaning.
Essentially, learning Regex is to learn the meanings of metacharacter, use them properly in your expression, and try to make your expression more efficient and readable.
Special Characters
Special Characters are related to the empty spaces and line returns in a document.
You just need to know that different operating system has its own way of using special characters to represent an enter keypress, in Windows, it uses \r\n, while in Unix-like system, \n is used.
Reference: https://stackoverflow.com/questions/3451147/difference-between-r-and-n/3451192#3451192
| Special Character | Meaning |
|---|---|
\t |
Tab |
\r |
Newline, CR (Short for Carriage Return) It just means to end the current line, not to start a new line. |
\n |
Newline, LF (Short for Line Feed) Unix and Linux use this to represent an enter keypress |
\r\n |
Newline, CRLF (Short for Carriage Return + Line Feed) Windows uses this to represent an enter keypress |
Example of using Special Character in Regex:

Figure 6: Match a Tab space

Figure 7: Match a pattern across multiple lines
4. Metacharacters with examples (Beginner)
Now let’s go through the metacharacters one by one with examples.
1. Wildcard Metacharacter -> . (magic dot)
If you want to find ‘git’, ‘get’ ‘got’ or any string with 3 characters, begins with g and ends with t, you should really try this magic dot.
This expression /g.t/g basically means, find any string starts with g, ends with t and has one character in between.
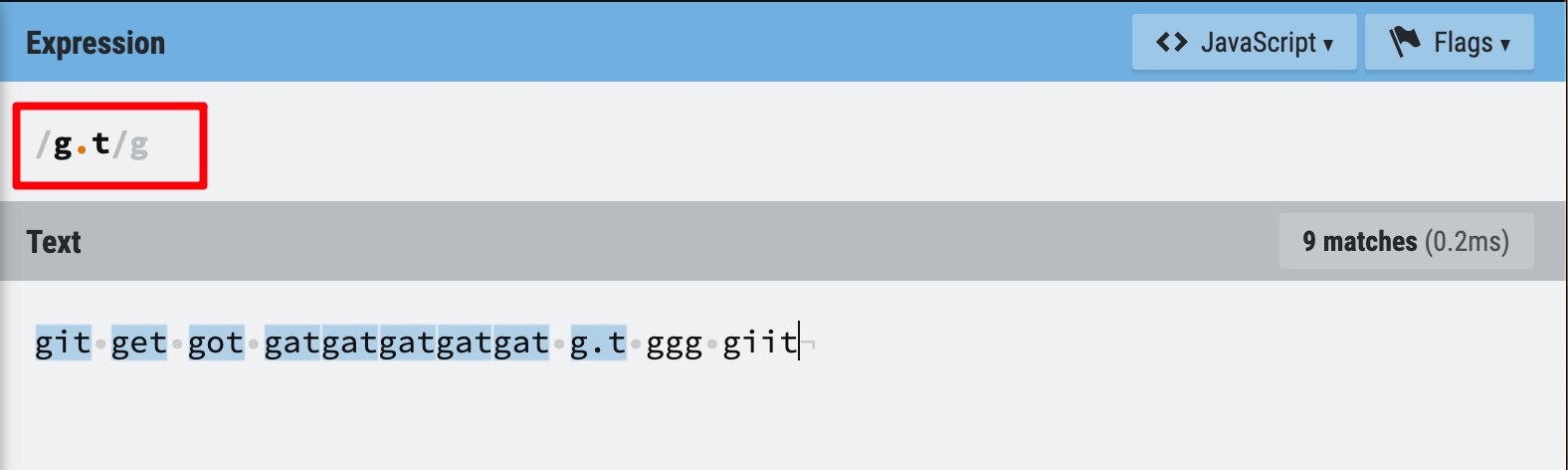
Figure 8: Wildcard metacharacter example 1
Tips for the magic dot usage
1. The magic dot will only match one character, so giit is not a match.
2. The magic dot is a metacharacter, so if you literally just want to find g.t , please remember to escape its special meaning -> use/g\.t/g
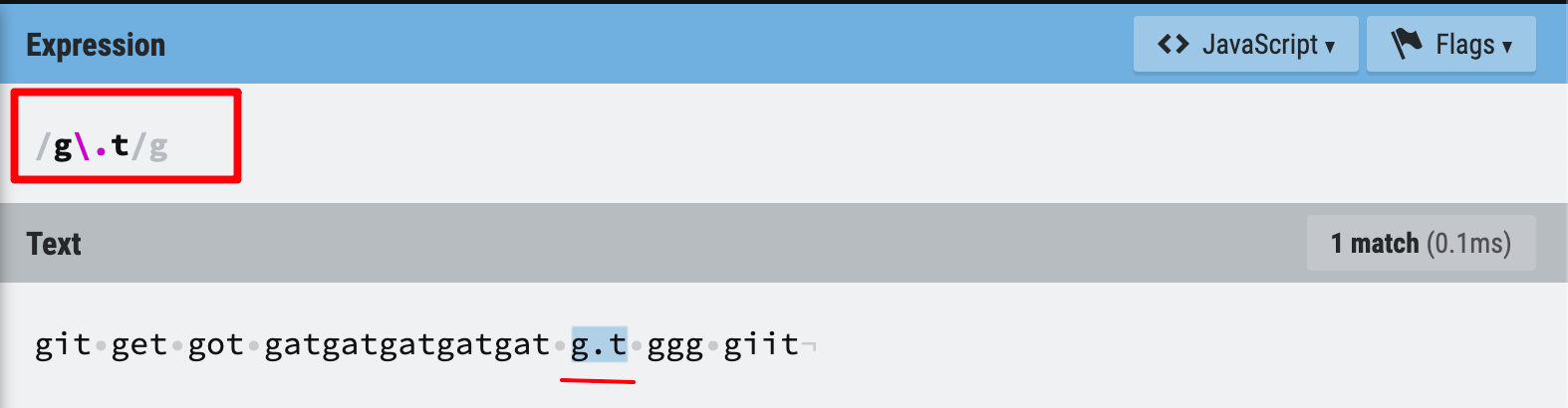
Figure 9: Wildcard metacharacter example 2
2. Escaping Metacharacters -> \ (backslash)
The escaping metacharacter is a guy who doesn’t like magic at all, any character with the escaping metacharacter before it will lose its magic power (Remeber how it turns the magic dot into a normal dot?).
By the way, the escaping metacharacter itself has magic power, so the best way to put it back to a normal backslash is to let it escape itself -> \\.
And another tip for you is to escape / when you want to use it as a literal character, because the slash can indicate the end of this Regex string.
Q: What about the start slash of the Regex string? Do we need to escape it as well?
A: The answer is no.
3. Enable more possibilities -> [] (brackets)
The official name of [] is to define a Character Set, I’d like to imagine it as a champion of enabling more possibilities for our Regex string.
For example, you want to match the word Organization in a document, but you know there’s another spelling for the same word, which is Organisation.
How to match both of them?
With the help of [], you can just use /Organi[sz]ation/g to indicate that you want to find all the Organization and Organisation in this document.
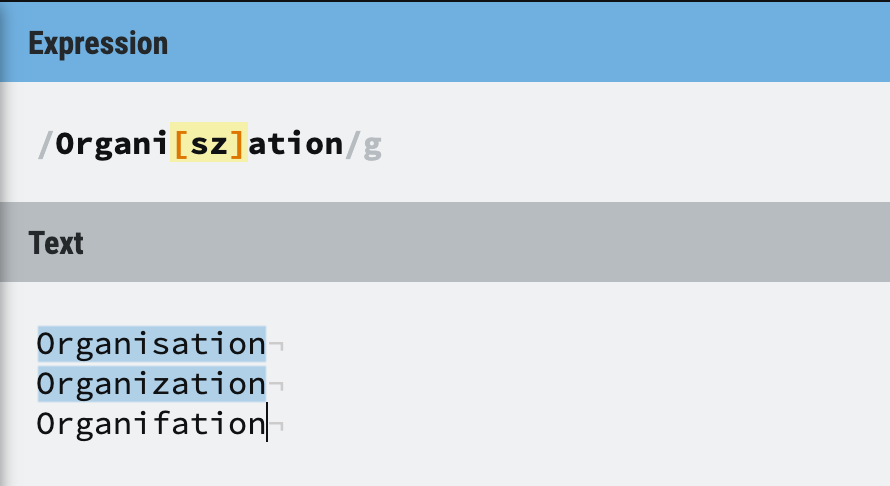
Figure 10: Character set example 1
One thing I do want to highlight is that, although we can match different characters with [], it essentially only represents one character, so /B[ae]d/ will match Bad and Bed, but will not match Baed.

Figure 11: Character set example 2
Tips - Brackets inside brackets
You can put as many characters inside the brackets as you like, but remember to escape the closing bracket ] if you want to use its literal meaning inside the character set.
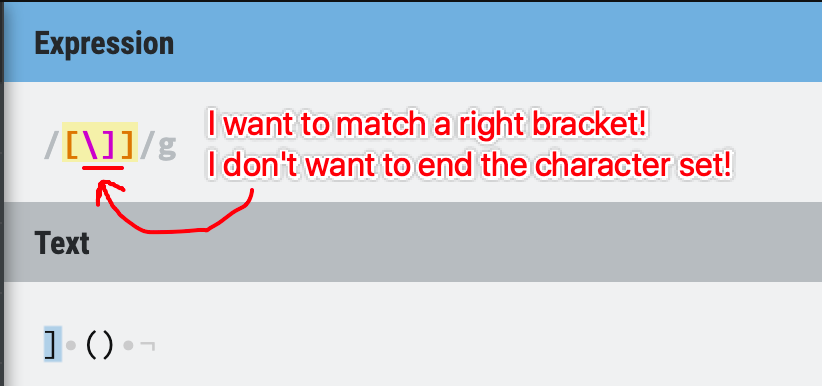
Figure 12: Character set example - special characters
What about the left bracket [, do we need to escape it inside the character set?
The answer is “As you like”.
You can go implicitly without escaping /[[]/, because the Regex engine is smart enough to infer that you just want to match a [, because you already have a [ before this one.
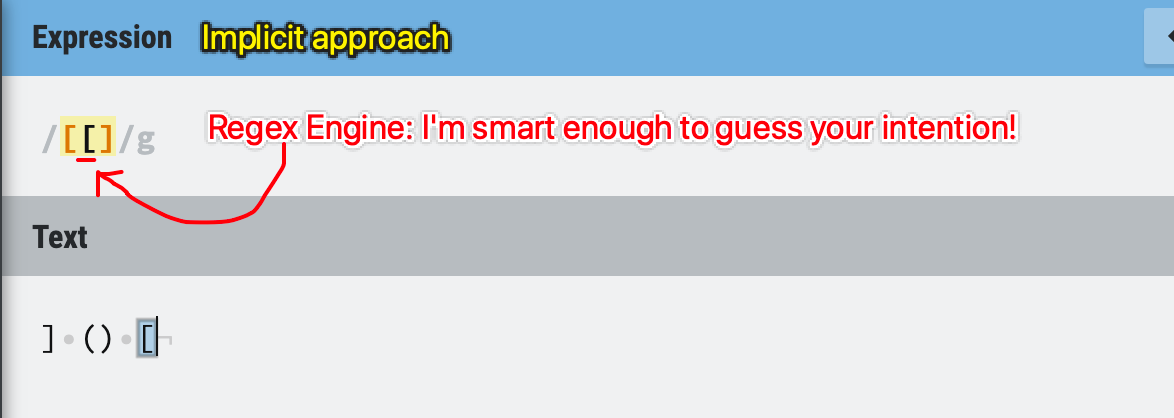
Figure 13: Character set example - implicit approach
You can also write a more explicit Regex string to do the same thing /[\[].
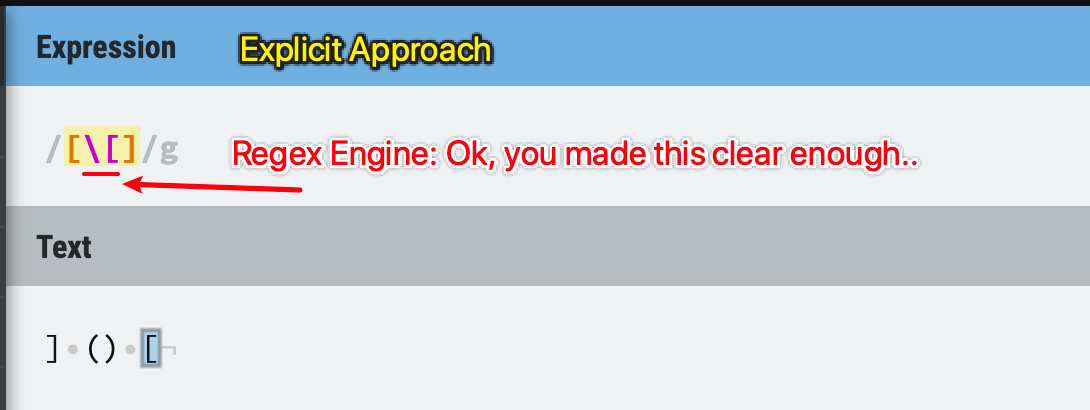
Figure 14: Character set example - explicit approach
Note:
Most metacharacters in the Reference Table are already escaped in the Character sets(implicit method), **however, it does no harm to escape them again **(explicit method).
Please remember that
],-^and\are NOT escaped implicitly in the character sets, so you will need to escape them in the character sets explicitly.
If you ask me, I prefer the explicit method, because it is more consistent and more readable. Anyway, we need to understand that there’re two different approaches, and both are correct.
I recommend beginners to escape any metacharacter in the Regex string. It’s a single rule, easier to remember and less mistake you could make.
4. Save some typing, use character range -> - (hyphen)
Being lazy can be good, if you can come up with an approach to do the exact same thing with less effort.
Now that we have the [] to enable more possibilities, sometimes we want to match any uppercase character or any lowercase character. You can type /[ABCDEFGHIJKLMNOPQRSTUVWXYZ]/, or you can learn a new way of indicating a character range -> /[A-Z]/ which does the same thing.
So let’s learn some commonly used character ranges to save us some typing time!
| Character ranges | Explanation |
|---|---|
[0-9] |
Match any number between 0 and 9 |
[A-Z] |
Match any uppercase characters from A to Z |
[a-z] |
Match any lowercase characters from a to z |
[A-Za-z] |
Match any character from a to z, case insensitive |
[a-f] |
Match any lowercase character from a to f This is an example of how you can use the range to customize your needs. |
Tips
If you want to match a number from 20 to 99, what Regex string should you use?
Someone wrote [20-99] to serve the need, but is it correct?
If you still remember the lesson from Character Set, you will know that [] only matches one character, and - indicates a range from the left character to the right character, in this case: 0 to 9.
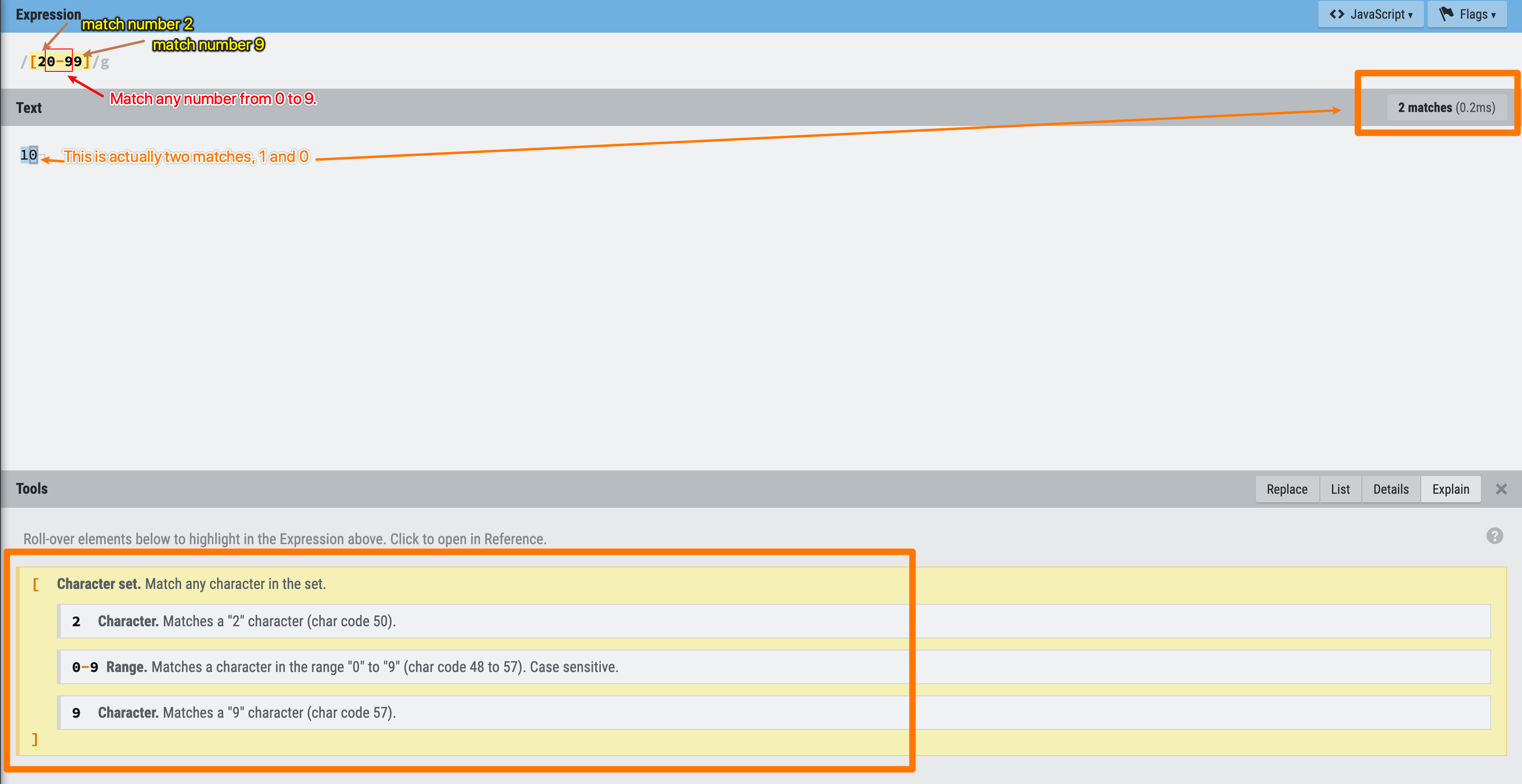
Figure 15: Character set example - number range
So really, [20-99] = [0-9] for the Regex engine.
Now think carefully, what is the correct Regex to match a number from 20 to 99?
Before revealing the answer, let’s keep learning more metacharacters! Maybe you can find some useful ones to solve this problem.
Shorthand Character Sets
As people get lazier, they feel even writing [A-Z] is costing too much effort.
So they come up with a shorter notation for commonly used ranges.
| Shorthand | Character Set | Explanation |
|---|---|---|
\d |
[0-9] |
Digit |
\w |
[a-zA-Z0-9_] |
Word Character (include _ but exclude -) |
\s |
[ \t\r\n] |
Whitespace |
\D |
[^0-9] |
Not a digit |
\W |
[^a-zA-Z0-9_] |
Not a word character (exclude _ but include -) |
\S |
[^ \t\r\n] |
Not a whitespace |
Basically, it’s just digit, word character, whitespace and all their opposite.
Please pay attention to the hyphen
-in the range, as-is a range metacharacter in the character set, so\wdoesn’t include hyphen-.If you want to escape any word character and hyphen, you can use
[\w\-].
5. I don’t want this -> ^ (Caret)
^ is a useful metacharacter called negative character sets, when you want to exclude something from your matching patterns.
It is useful when you want to keep all the other possibilities, just exclude something you don’t like.
For example, if you want to search for a three-character string, starts with Y, ends with s, the middle character, you don’t want e, you want anything else.
Then you can use /Y[^e]s/ to find your matches. This could be useful to find some misspelling words.
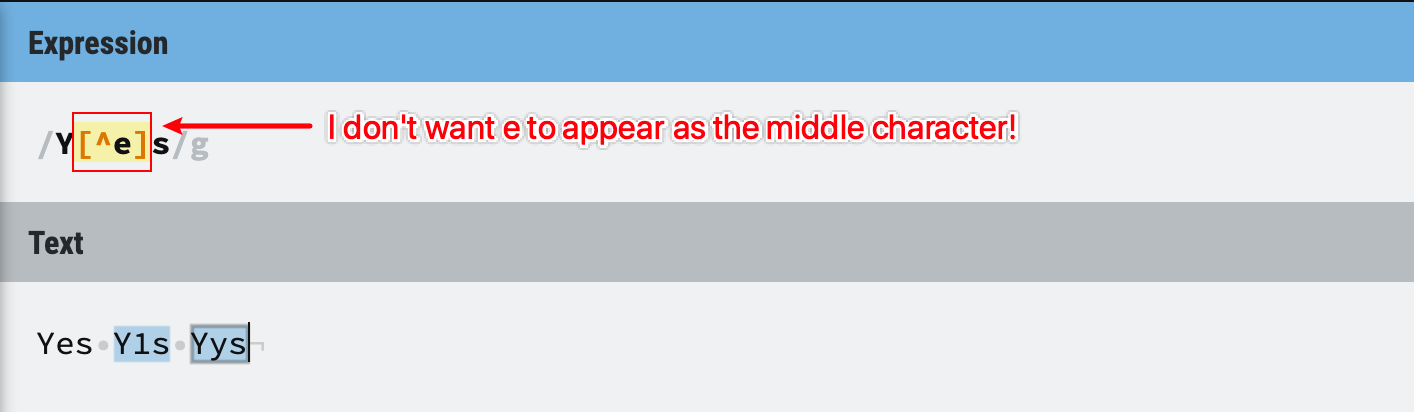
Figure 16: Negative character set example 1
Tips - it has to be something
When dealing with this metacharacter, please keep in mind that the Regex[^e] is still trying to match one character, it’s just cannot be e, but it has to be something, even a space or a Tab will be fine!
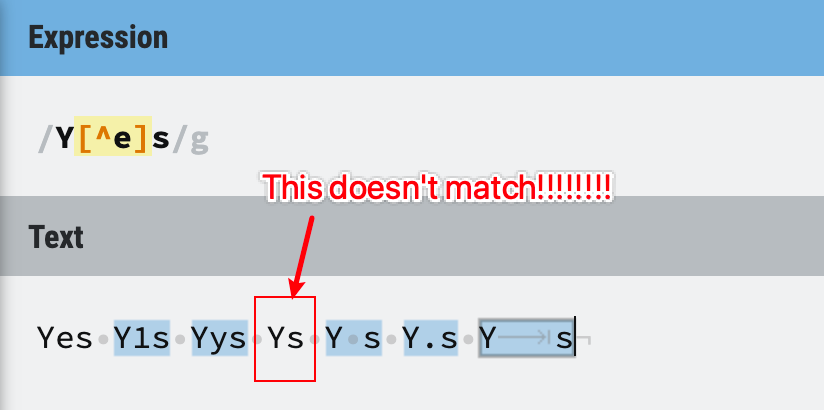
Figure 17: Negative character set example 2
Tips - use with range
Negative character sets can also be used with range, like this:

Figure 18: Negative character set example 3
Tips - the location of ^ matters
1. If you decide to use negative metacharacter in the character set, all the characters/character ranges will be excluded.
2. So you cannot think, I want to exclude xxx but also include yyy, if you use ^ at the start of a character set, it will become a negative set.
3. And if you are not putting ^ at the beginning of the character set, it will not be treated as a metacharacter, see example below.

Figure 19: Negative character set example - location
When
^is not used inside a character set, it can mean something else, we’ll explain it in the “Start and End Anchors” Section.
6. How many times?
Repetition metacharacters
Sometimes, you don’t know whether a character would appear in the pattern, it can be there, or not there.
Sometimes, you are sure a character is there, but not sure about how many times it would appear, maybe once, maybe twice, maybe 10 times.
Sometimes, you are sure that a character will be there for 1 time, or not there at all.
With all the possibilities, people have assigned some special meaning for 3 characters, to indicate the times that a character should appear in a pattern.
1. * means 0 or more times
2. + means 1 or more times
3. ? means 0 or 1 time

Figure 20: Repetition metacharacters example 1

Figure 21: Repetition metacharacters example 2

Figure 22: Repetition metacharacters example 3
Note: we will discuss how to add word boundaries later, so that substring
appleinsideappleeeeeewon’t be a match (as the whole word doesn’t match).
Examples of using repetition metacharacter:
1. use repetition with . (any character): /.+/ = match any character string except a line return;
2. use repetition with character set: /\d+/ = match any number (e.g., 1234);
3. use repetition with character range: /[a-z]+ing/ = match any lowercase words ending in “ing”
4. use repetition for different spelling: /labou?r/ = match labour and labor.
Quantified Repetition
Sometimes, use only the above 3 repetitions is not enough for our needs. If we want a character to repeat at least 3 times, but no more than 5 times, what should we do?
The answer is to use quantified repetition, which is {} - the curly brackets.
Inside the curly brackets, you can specify a range, or a number. -> {min, max}
Examples of using quantified repetition:
1. /[A-Z]{3}/ = match a string with 3 uppercase characters
2. /[A-Z]{3,5}/ = match a string with 3 to 5 uppercase characters
3. /[A-Z]{3,}/ = match a string with at least 3 uppercase characters
4. /[A-Z]{,5}/ = THIS WON’T WORK
Essentially, we can use
{0,1}to replace?, use{0,}to replace*,{1,}to replace+.So the 3 repetition metacharacters are just some shorthands for writing these quantified repetitions.
Congratulations on completing the beginner metacharacter section!
I’d recommend you to take a break before moving into the mid-level section.
5. Metacharacters with example (Mid-level)
If you are ready for more interesting metacharacters, let’s continue now!
1. Grouping and alternation
Grouping metacharacters () (brackets) can be used to help you group patterns together, for example:
/(ab)(cd)e/ and /abcde/ are two ways of matching abcde.
While the alternation metacharacter | (pipe) is acting as an OR operator in the Regex, for example:
/a|b/ means match a and b.
You can also use multiple alternations, like /a|b|c/ to match a and b and c.
Why do we need grouping and alternation?
You might be wondering, why we need to grouping and alternation in Regex string? Let me tell you what are the common use cases for using them.
1. You want to apply the repetition operators not only to one character, but to multiple characters.
If you find yourself writing /a+b+c+/ for matching aabbcc or abc, consider to use grouping metacharacters like this /(abc)+/.
2. You want to enable alternation for the matching pattern.
For example, when you want to match abcd and efgd, you don’t need to write /[ae][bf][cg]d/ if you know how to use grouping and alternation metacharacters properly, you can write /(abc|efg)d/ to do the same thing.
3. You want to replace/reformat a part of the Regex matches, not all of them.
For example, if you want to replace both Apple pie with apple and Banana pie with banana with xxx cake has xxx , you can write /(Apple|Banana) pie with (apple|banana)/ to find the matches, then use $1 to indicate the first group (Apple|Banana) and use $2 to represent the second group (apple|banana).
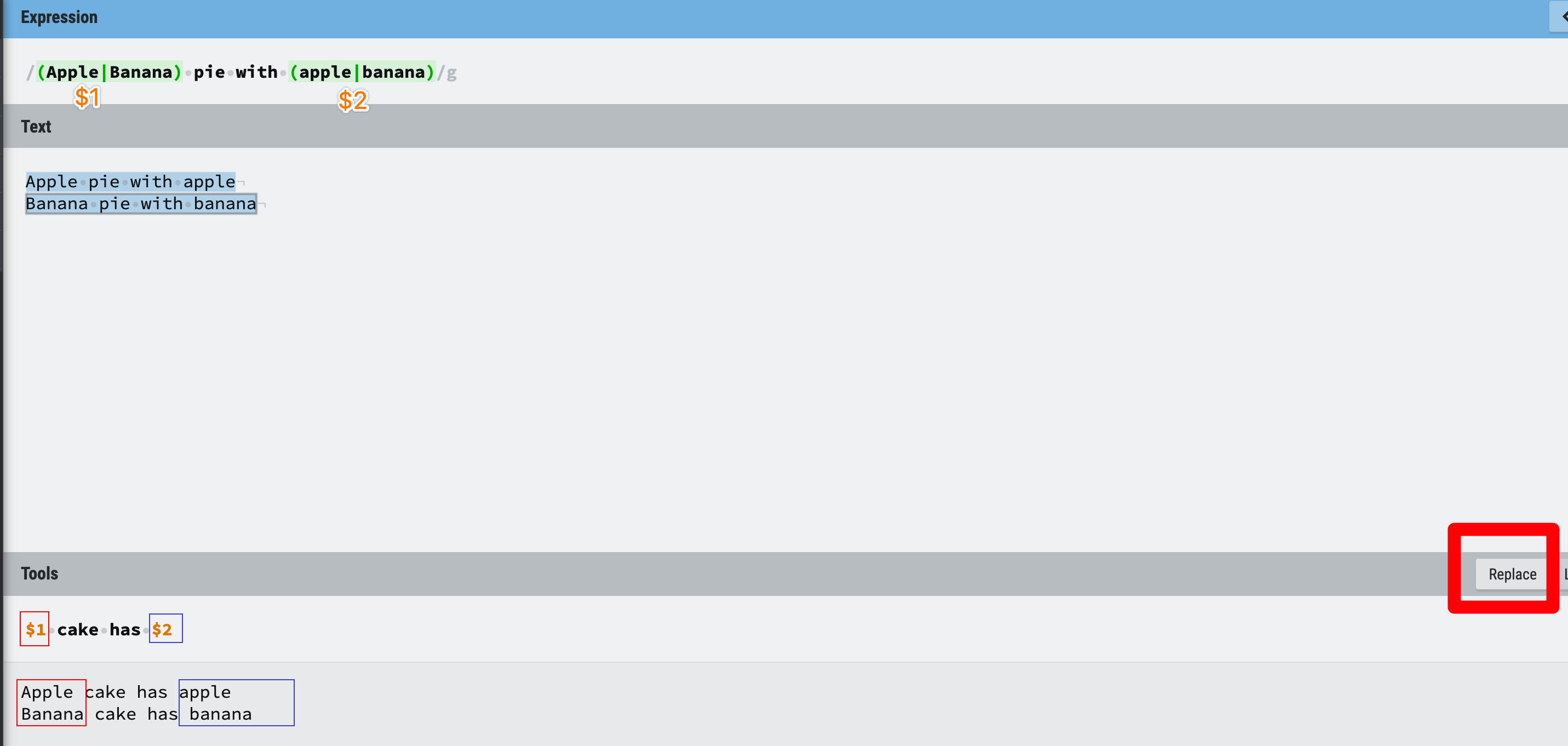
Figure 23: grouping and alternation example 1
We can also reformat the string with the help of grouping, like this example, isn’t it helpful?
Figure 24: grouping and alternation example 2
Note: some regex engine might not support
$for representing groups, try\$if you have any issue.
Grouping and alternation are usually used together, but you can also use them separately based on your needs. They are useful tools, so make sure you understand them!
Tips - be careful with grouping!
Look at the phone number example above, we are using /(\d{2})-(\d{4})-(\d{4})/, not /(\d){2}-(\d){4}-(\d){4}/, do you know why?
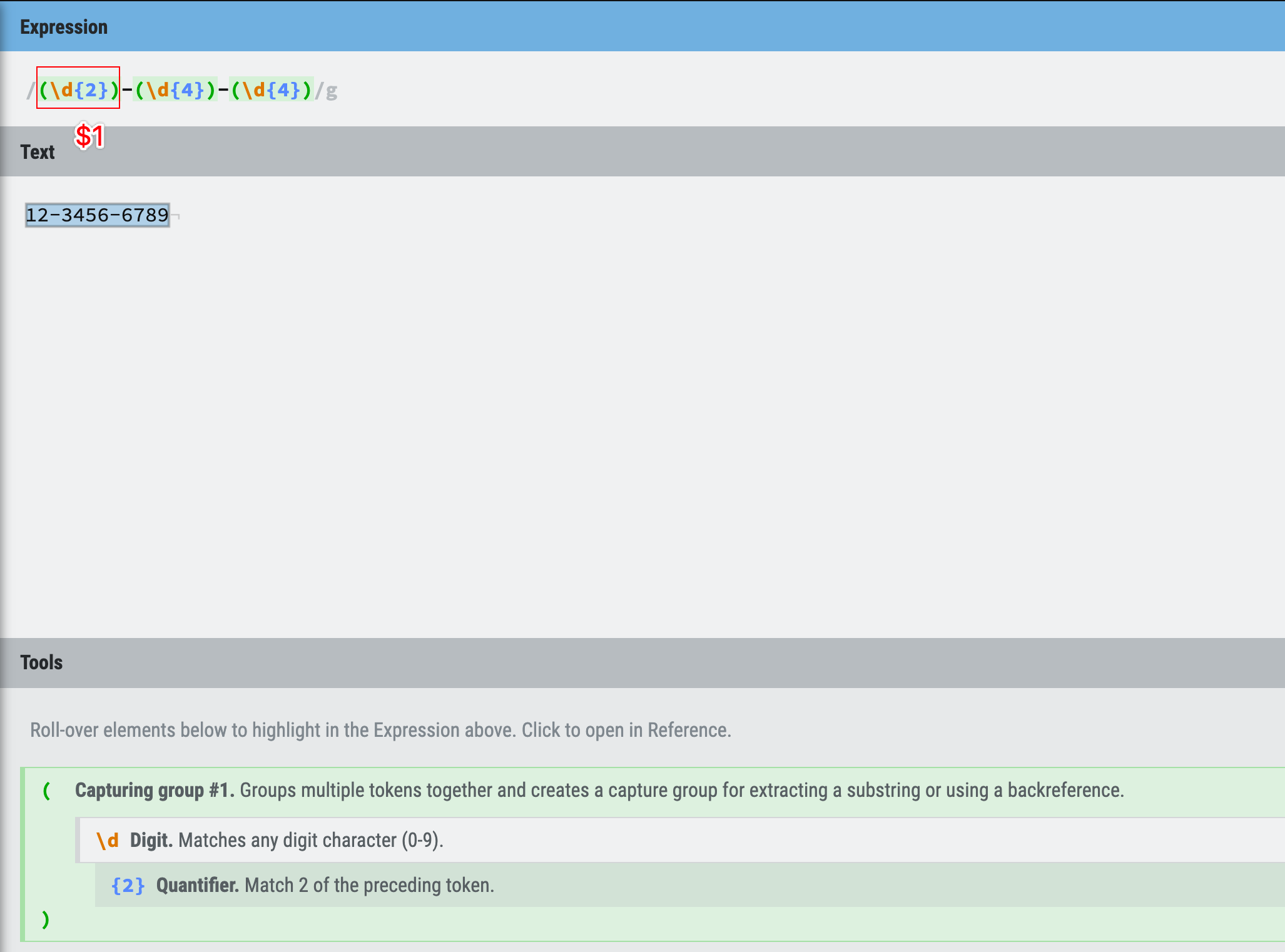
Figure 25: grouping and alternation example 3
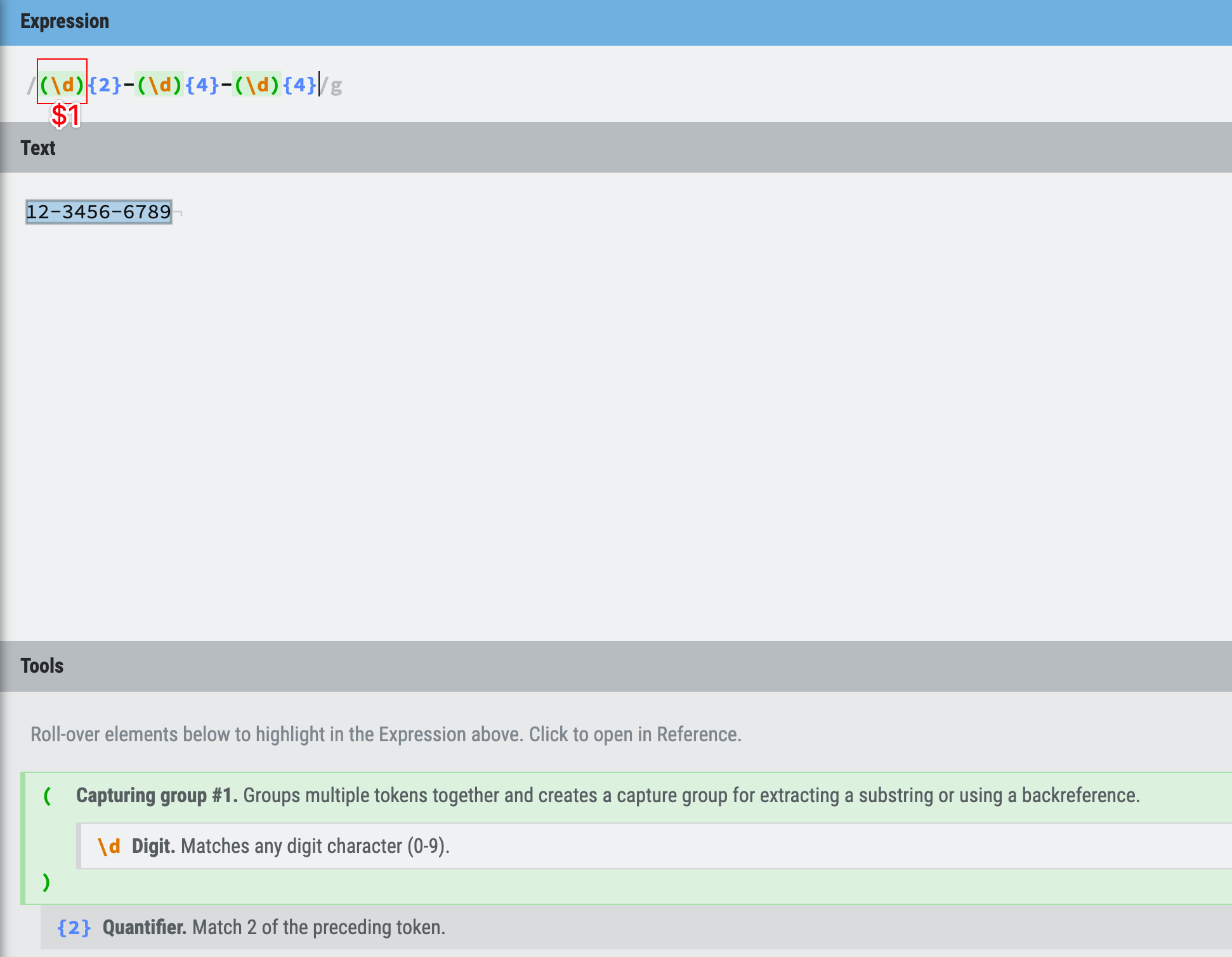
Figure 26: grouping and alternation example 4
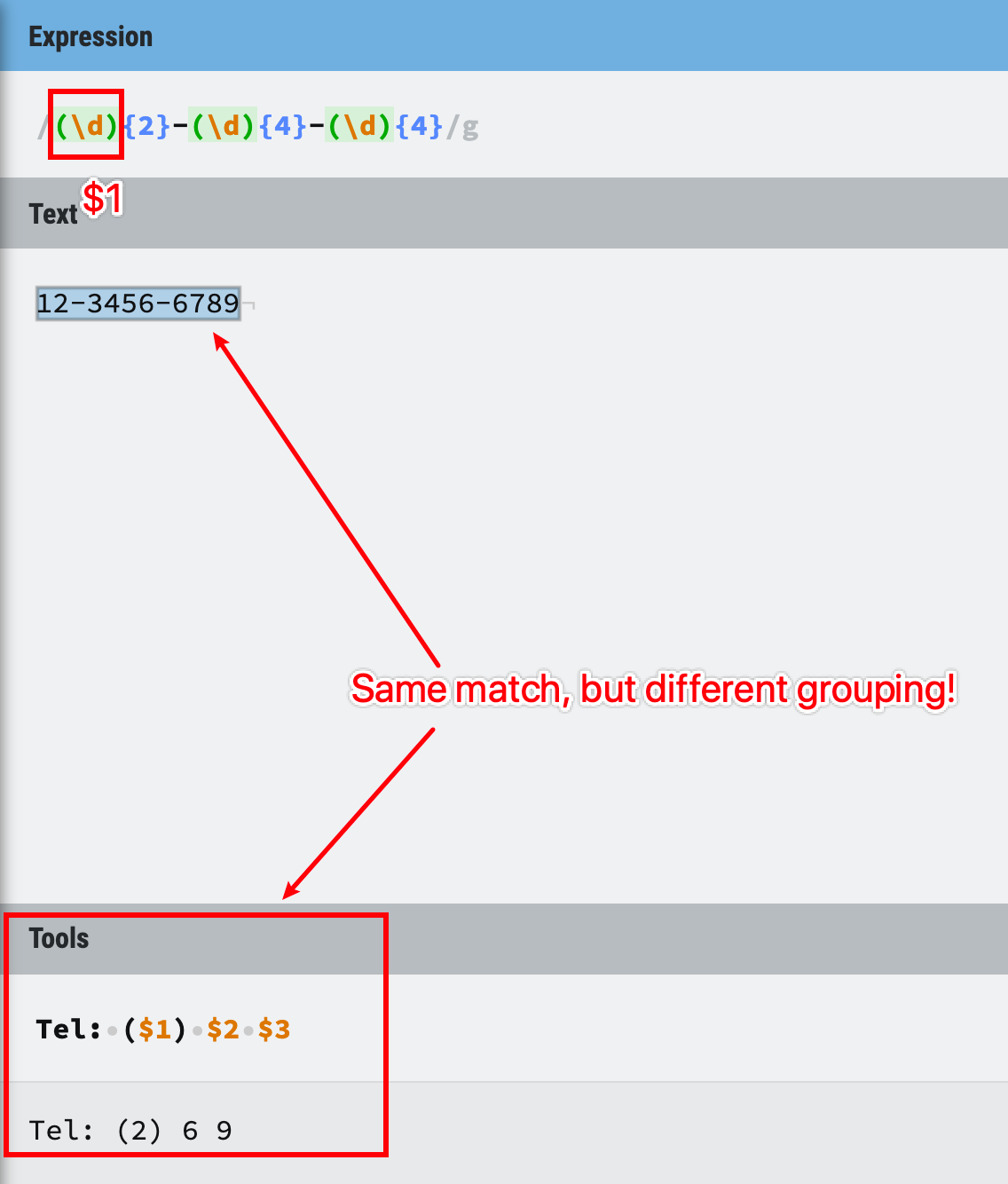
Figure 27: grouping and alternation example 5
This kind of mistake can make beginners scratching their heads for a while, so please be mindful when you are dealing with grouping, put the closing bracket at the correct location!
2. Anchors -> start and end
Anchors are used to defining the start/end of the string/line in Regex.
But why we need this? Let’s look at an example:
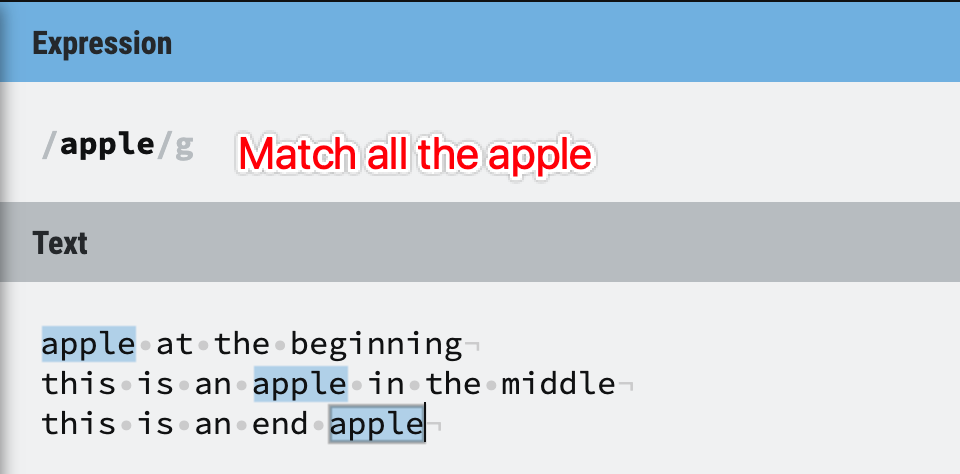
Figure 28: Anchors example 1
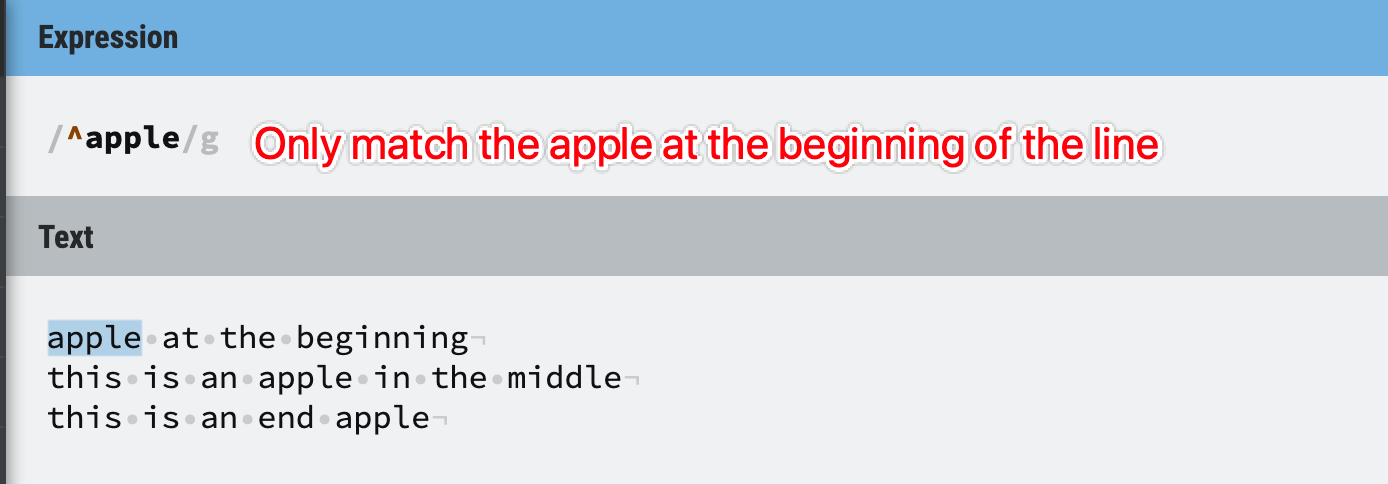
Figure 29: Anchors example 2
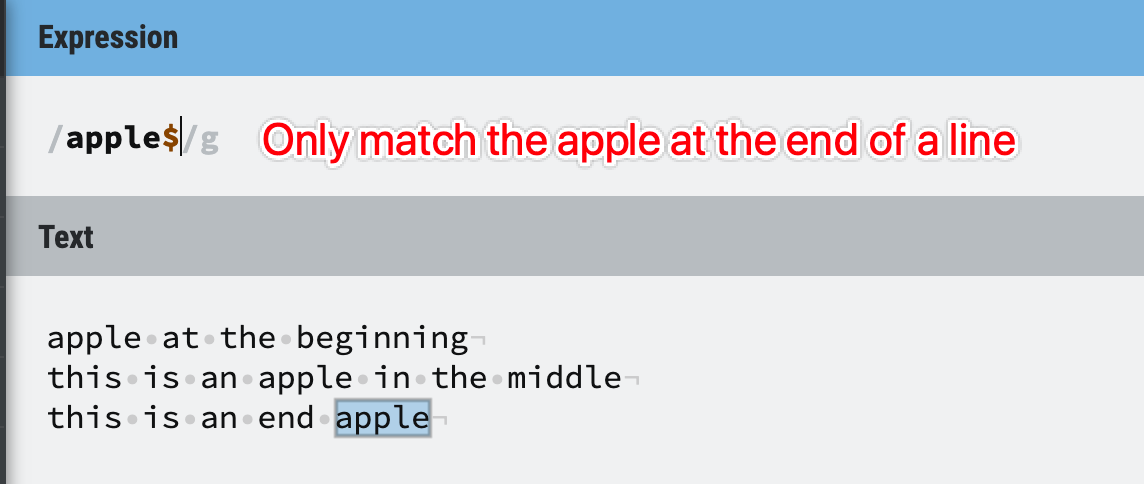
Figure 30: Anchors example 3
1. ^ and $ are supported in all regex engines;
2. \A and \Z are supported in all modern regex engine (except JS);
3. so we cannot use \A and \Z in JS regex for the start and end anchor.
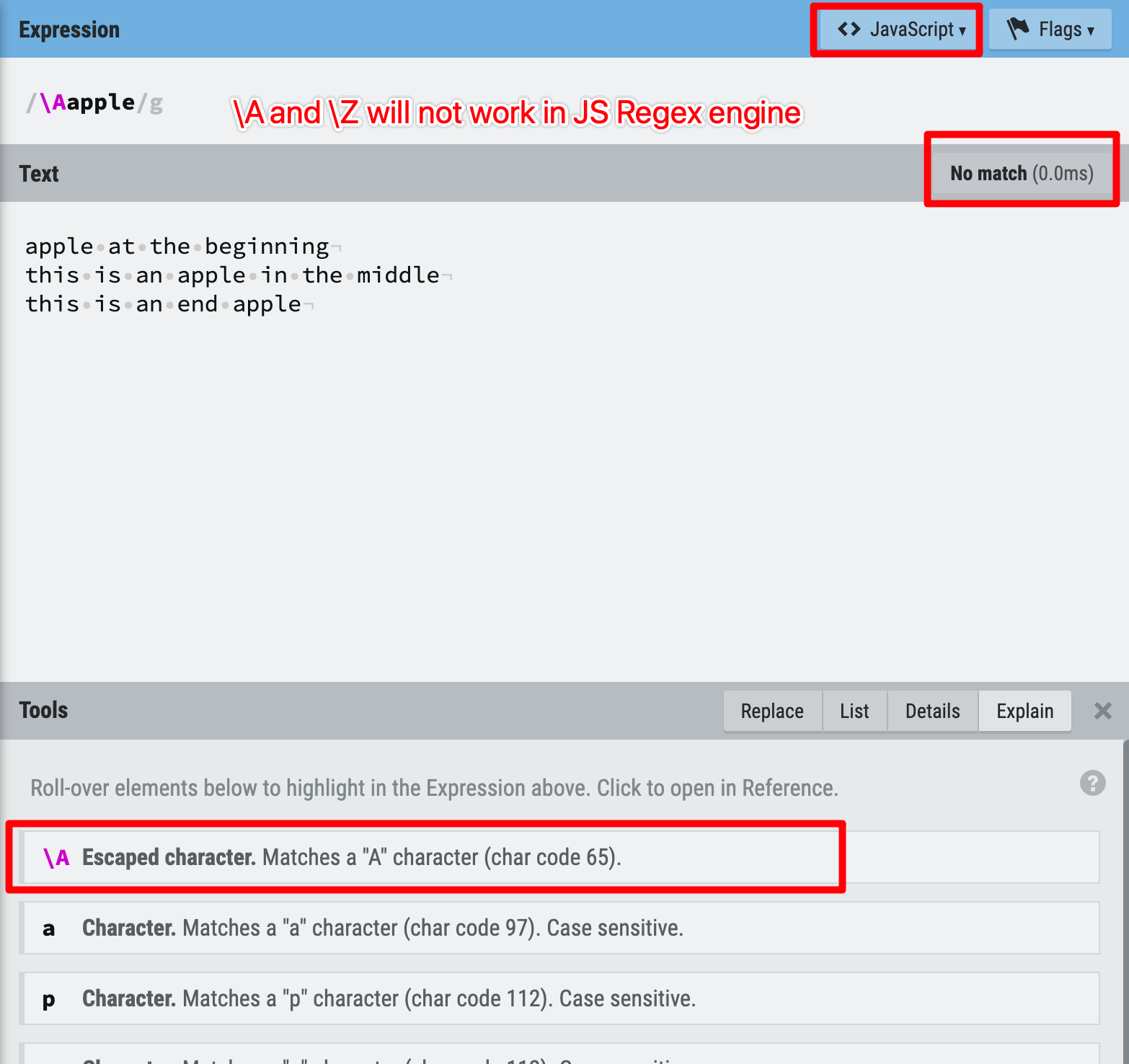
Figure 31: Anchors example 4
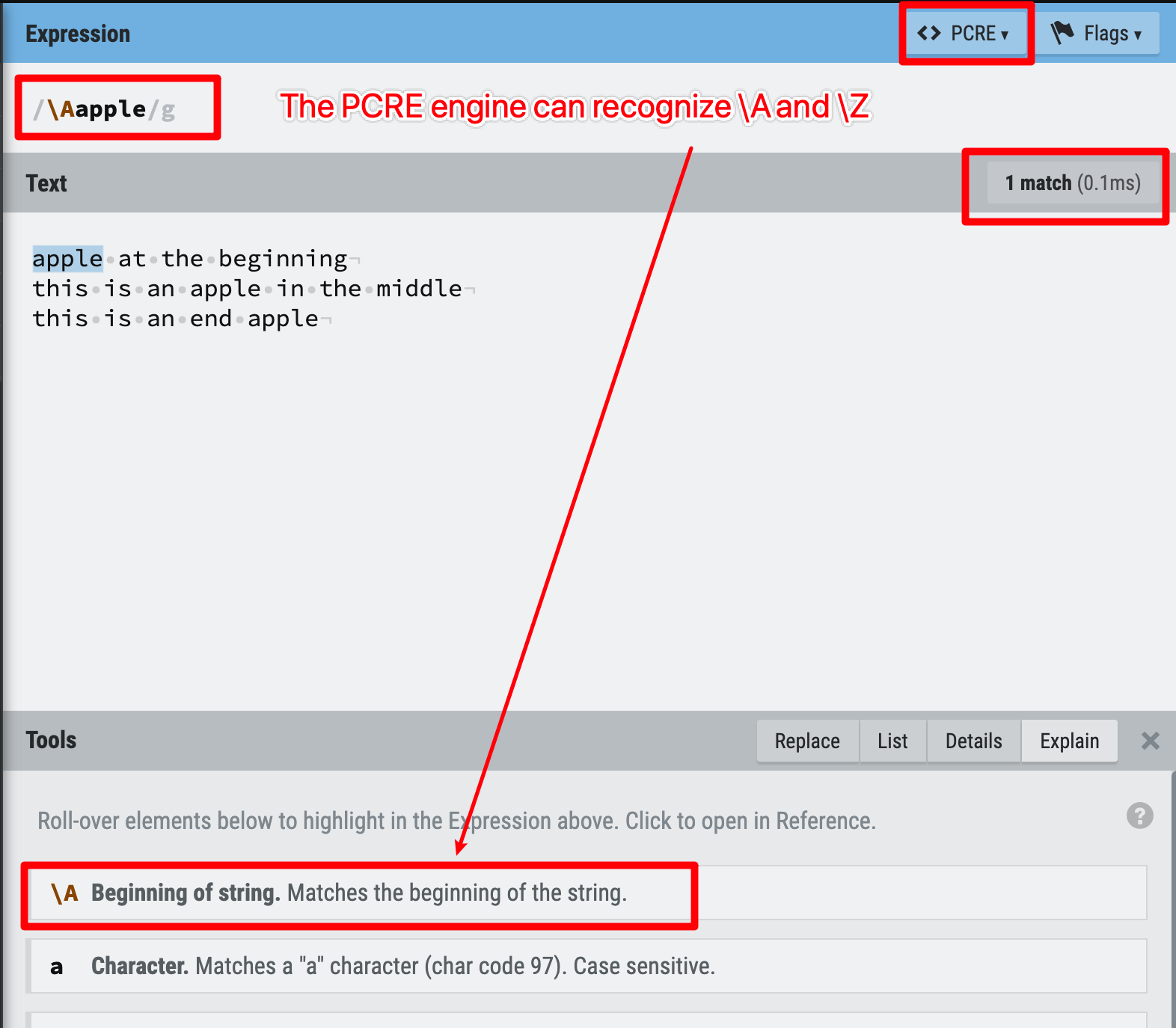
Figure 32: Anchors example 5
3. Multiline mode and single-line mode
I think this is perfect timing to introduce the multiline mode and single-line mode, because they’re used associated with start and end anchors.
In the single-line mode:
^ and $ do NOT match at line breaks.
\A and \Z do NOT match at line breaks.
In the multiline mode:
^ and $ do match at line breaks.
\A and \Z do NOT match at line breaks. (same as the single-line mode)
In summary, the multiline mode only works with the ^ and $, when multiline mode is ON, Regex engine will treat each line as the start of the string, not just the first line of the whole document.
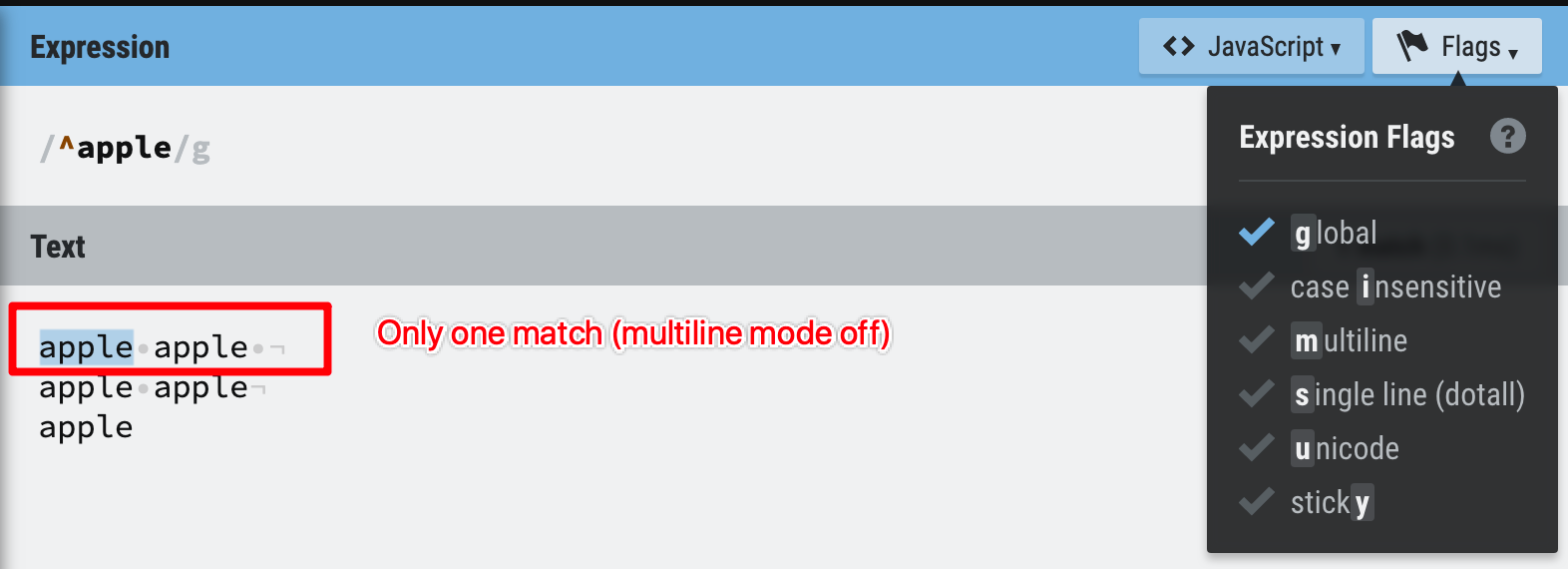
Figure 33: multiline mode off

Figure 34: multiline mode on
Multiline mode off

Figure 35: multiline mode off
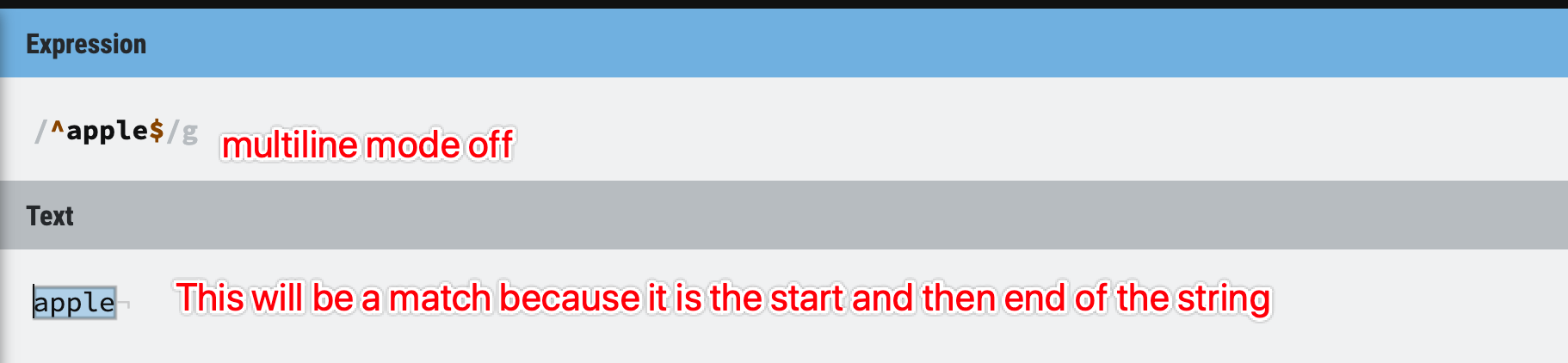
Figure 36: multiline mode off
Multiline mode on
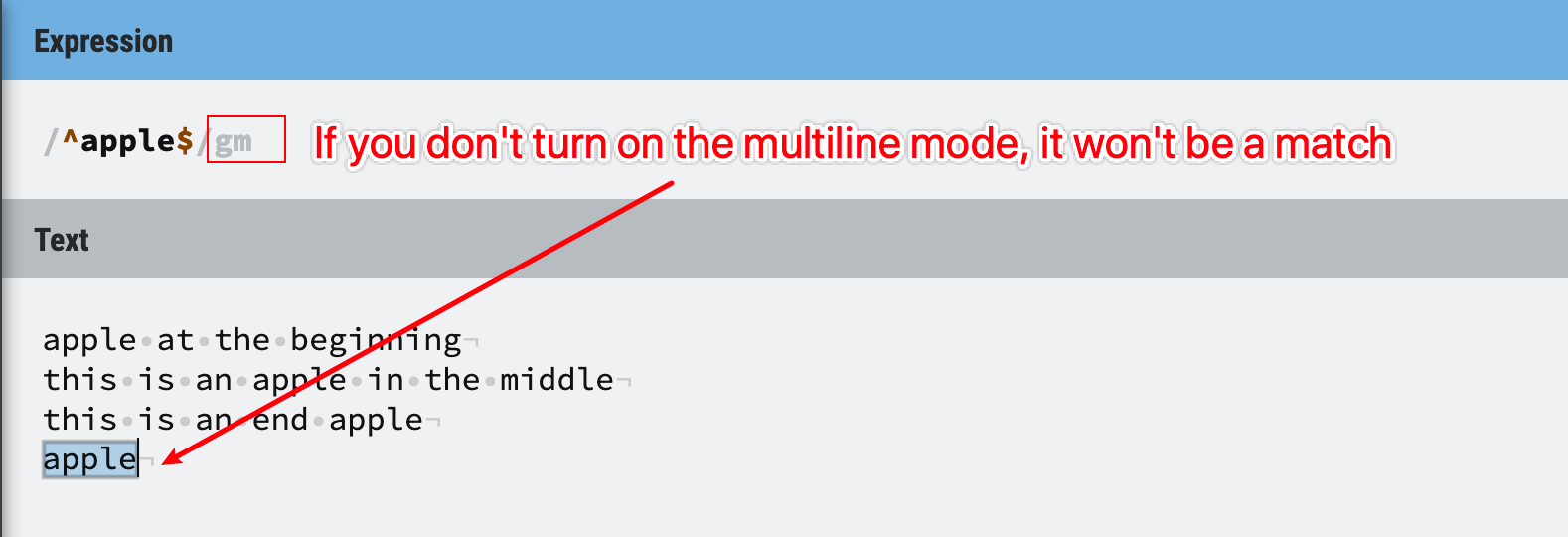
Figure 37: multiline mode on
4. Word boundaries - Start/End of a word
The last metacharacter to learn is \b and \B, they are used to set a word boundary for our matches.
1. \b Word boundary (start/end of a word)
2. \B Not a word boundary
If you still remember, in the repetition metacharacter section, the substring apple in applee is also regarded as a match.

Figure 38: Word boundaries
What if we just want to find the exact word apple and appl? We can use word boundaries to help us.
If we add word boundary at the end, the single e or l will be the end of the word, but we didn’t set the word boundary at the beginning, so Aapple’s substring will still be a match.

Figure 39: Word boundaries
Let’s set the start and end boundary to get exactly what we want:
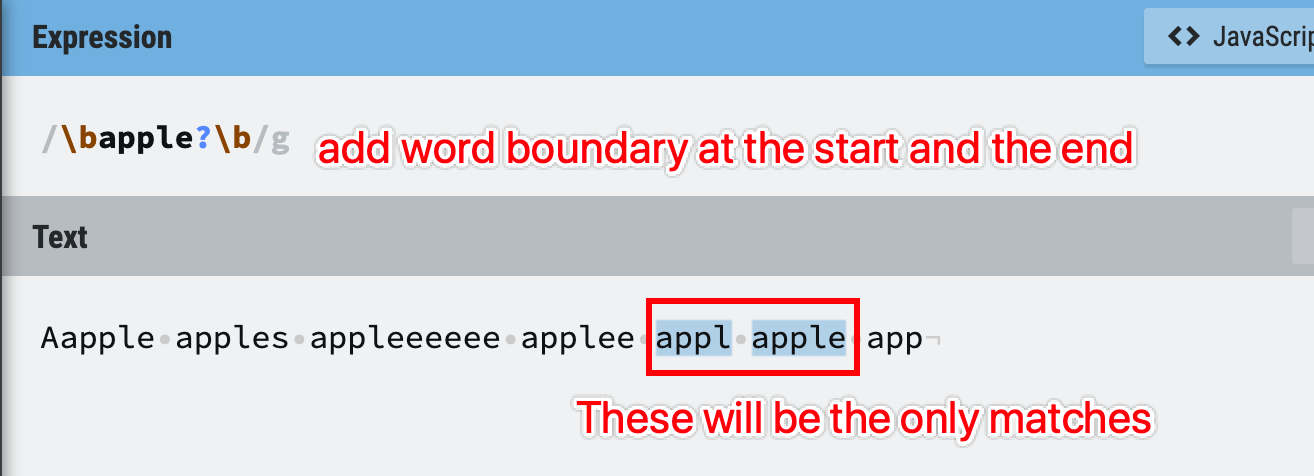
Figure 40: Word boundaries
Tips - be careful with \w
One common trap for beginners is trying to use /\b\w+\b/ to match any word, recall that \w only represents /[A-Za-z0-9_/ , so the little hyphen is not included.
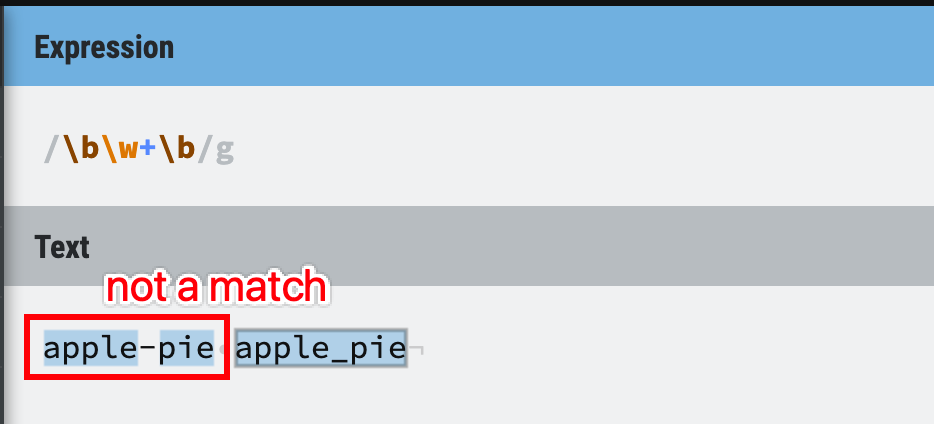
Figure 41: Word boundaries
The solution is simple and easy, just use a character set to include the hyphen.
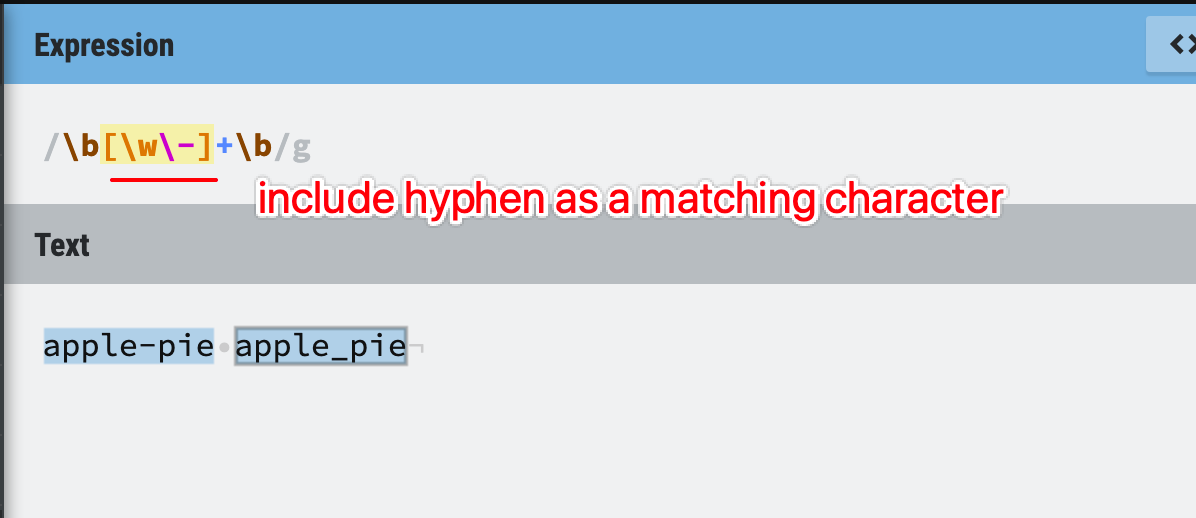
Figure 42: Word boundaries
Tips - \B use cases
What is the use of not word boundaries? It may not be as frequently used as the \b, but remember it is there when you need it.
Example 1: Use \B to extract numbers between underscores.
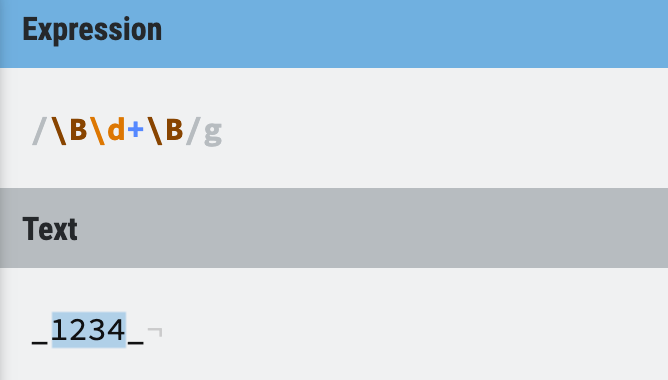
Figure 43: Word boundaries
Example 2: Use \B to get some character combinations in the middle of the word.
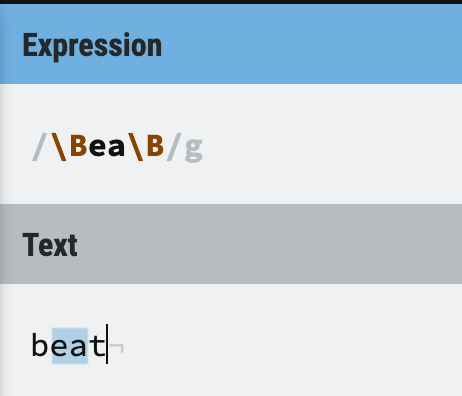
Figure 44: Word boundaries
6. Summary
What you have learnt
This tutorial has covered the following topics:
1. What is Regex and why it is useful for everyone working with text;
2. Regex flags and Regex engines;
3. Three types of characters - literal, metacharacter, special character;
4. Explanation, use cases and tips for each metacharacter.
Afterwords
This is the end of my (very long) Regex tutorial for everyone, hope you find it interesting and easy to follow, because I have really put a lot of effort and hard work in writing this post.
As a beginner, I always find the key to learn something is to find a well-written tutorial to follow, I spent a lot of time trying to find a good Regex tutorial, and to be honest, there aren’t too many.
Regex is not easy to learn and beginners always get trapped and bored in those metacharacters, and I can guarantee that you need to come back again for some clarification because there’s just too much information and knowledge to absorb in one day!
Feel free to come back, review some sections, and make use of the Reference tables for a quick search.
Thanks for reading and learning with me.
What’s next?
I’ll explain some advanced Regex topics in another post, such as the difference between Greedy and Lazy, and how to make your Regex matching more efficiently by understanding how the Regex engine works internally.
It will be very useful for anyone who wants to master Regex, and believe me, I’ll make it as easy to understand as usual!
So stay tuned, looking forward to seeing you again!
Talk to Luna
Support Luna

