

Luna Tech | Advanced Regex Tutorial for Everyone

1. Brief
Hi everyone, welcome back!
I hope you have read my last post “Regex tutorial for everyone” and enjoyed it. In this post, as promised, I’ll discuss some advanced topics with you.
2. Greedy and Lazy
Let’s get to know our Regex engine’s personality more, Regex engine needs to make its own decision when there’re multiple possibilities for matches. And this decision often comes with quantified metacharacters.
Recall that quantified metacharacters allow you to specify how many times you want a character to repeat.
+: at least 1 time
*: 0 or more times
?: 0 or 1 time
{min, max}: define it as you like
Greedy - default behavior
Look at the example below:

Figure 1: Greedy example
What happened between you and the Regex engine?
Let’s try to understand the Regex first:
1. The g is just a normal character matches g;
2. The .+ means match any one character (at least one time), it is a special character (remember we talked about it in the previous tutorial, and feel free to look it up from the Regex Reference Tables);
3. And the o is just a normal character matches o;
But why it gives you goooooooooooooooooo instead of goo or gooooo?
What makes the Regex engine made this decision?
The answer is that: Regex engines are GREEDY in nature! It will try to get as many as it can, just imagine a greedy person who always wants more!
And this will be your conversation with the Greedy Regex engine:
You: Regex engine, find at least 1 any character after
gand also, I want to have aoat the end, start searching!Greedy Regex engine: Let me see if I can get you as many
oas possible!Greedy Regex engine: Look! I’ve got a lot of
os afterg, hope you like this result!You: Okay, you are really working very hard…
And in the next example, the Regex engine did exactly the same thing! It gives you 5 os because this is the maximum number of repetitions it can find!

Figure 2: Greedy example
Lazy mode
Okay, it’s nice to have someone who is trying to give you as much as they can (in this perspective, I think Regex Engines are actually very generous because they always offer you more). But human beings are difficult to be satisfied, sometimes you want more, sometimes you want less…
And if you actually don’t want to have as many repetitions as possible, you can simply add a ? after the quantified metacharacter, it will enable the lazy mode and you will be given as little as possible for the matching result.
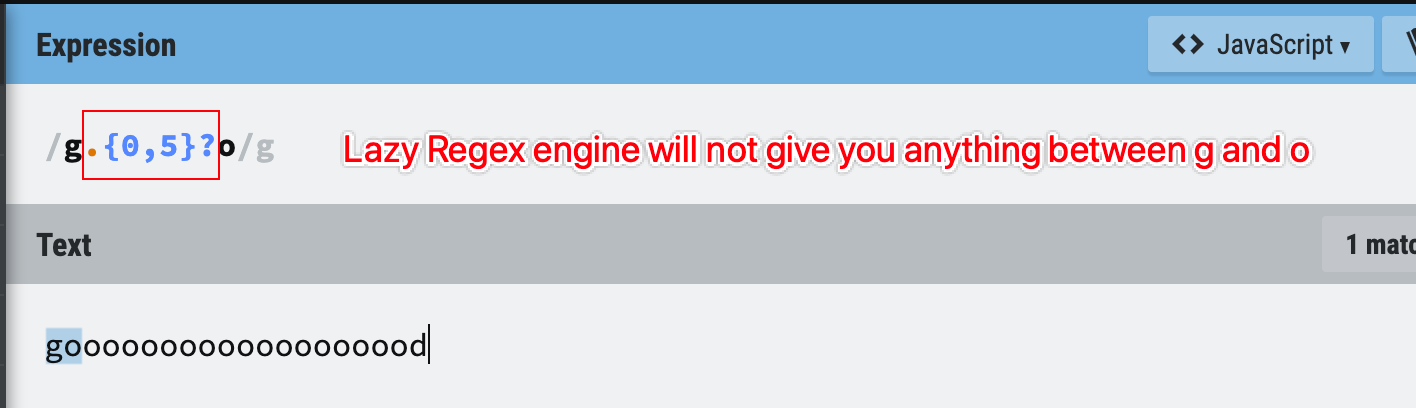
Figure 3: Lazy example
Are you confident that you have understood the greedy and lazy concept now?
Let’s take a look at the following example, there’re two repetition metacharacters in the expression, both can be greedy or lazy, I’ll explain which part of the regex matches which part of the string in 4 different scenarios. I believe after reading this part, your Regex knowledge will level up!
Scenario 1: both greedy

Figure 4: Scenario 1 - both greedy
Answer:
.+ will try to match as many as possible, but it will give the last two letters to other regex patterns to make the string match.
It is greedy in the sense that it will give as little as possible to serve other pattern’s needs.
Although \w+ is meant to be greedy as well, but first come first serve, it has nothing more to grab..

Figure 5: Scenario 1 - both greedy
Scenario 2: first lazy, second greedy

Figure 6: Scenario 2 - lazy and greedy
Answer:
In this scenario, .+? becomes a lazy expression, so it will match as little as possible, just 1 o.
And the \w+ part has got 4 o left to match, since it is greedy, it will grab them all!
So although in this scenario, the final result is the same as the scenario 1, the Regex engine actually matches different parts with different patterns, that’s why this is an advanced topic!

Figure 7: Scenario 2 - lazy and greedy
Scenario 3: first greedy, second lazy

Figure 8: Scenario 3 - greedy and lazy
Answer:
This is similar to scenario 1 because the greedy pattern has taken so many characters and there are only 1 left for the \w+, so it doesn’t matter whether it is lazy or greedy, it can only get 1 o.

Figure 9: Scenario 3 - greedy and lazy
Scenario 4: both lazy
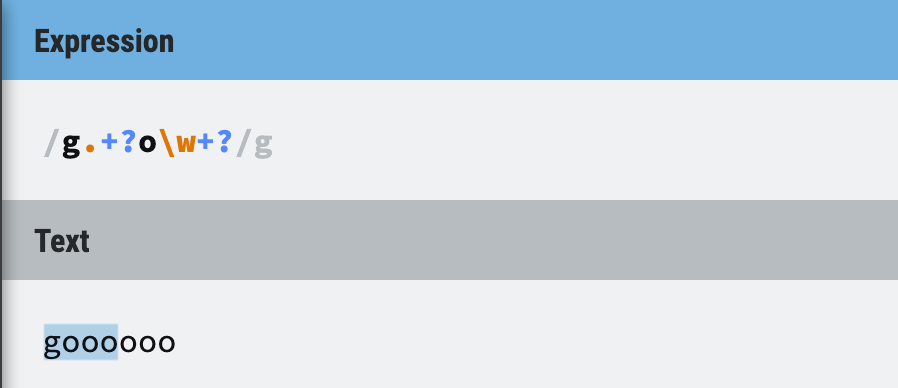
Figure 10: Scenario 4 - both lazy
Answer:
For the first time, we got a different result! And this is because both repetition metacharacter is trying to match as little as possible.

Figure 11: Scenario 4 - both lazy
3. Regex Efficiency
Writing a Regex pattern in different ways could affect the Regex engine efficiency, let’s look at an alternation example:
If we want to find like and hate and enjoy in the string, we use alternation and put all three words inside.
Let’s think about what are the possible ways for the Regex engine to find a match.
One way could be, take the first alternation (like) and try to find a match in the entire sentence, if it cannot find any, try the second alternation (hate) and go to the first character of the sentence, try to find a match…
The other way could be, take the first character, see if it matches the first character in the first alternation (l), if not, see if it matches the first character in the second alternation (h), if not, try the first character in the third alternation…
Which way does the Regex engine use?
The second one!
Wait, how to prove it? How can you be sure that it is not using the first method?
Look at the example below, if the first approach is used, first will be matched for the whole string, and first will be found before second, but we are getting second as the first match (with global mode turned off), this is the proof of Regex engine’s internal matching approach, it is using the second approach.
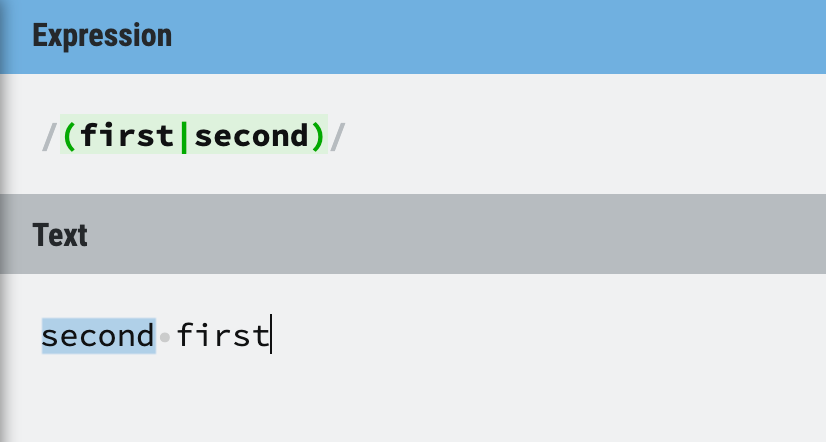
Figure 12: Regex matching mechanism
The Regex Engine is also eager
From the above example, we also notice that the Regex engine is eager, which means it will return the first match to you, maybe not the first thing you want.
Maybe you are trying to define the priority of first and second by putting them to a different position in the alternation, but unfortunately, the Regex engine doesn’t care, because of its internal matching mechanism.
Why this matter?
Because this makes the order of alternation important, imagine if you put \wike as the first alternation, any word character will match the first character, right? Then the Regex engine needs to try the second character in the first alternation, and maybe it matches, maybe not, but it needs to spend some time and try.
If the Regex engine can exclude an alternation as early as possible, it can move to the next alternation and the overall efficiency can be improved.
So the rule of thumb is that: Always put the simplest expression first when using alternations.
Exercise: Regex Efficiency
Order the following Regex based on matching the efficiency and create an alternation pattern:
1. /.+_cake/
2. /small_cake/
3. /\w{3,5}_cake/
Answer:
Order of the Regex efficiency: 2 > 3 > 1 (2 is the most efficient one)
Alternation pattern: /small_cake|\w{3,5}_cake|.+_cake/ (same as the efficiency order)
Exercise: Eager
If you want to find not and nothing in a text file, which Regex would you use?
1. /no(t|thing)/
2. /no(thing|t)/
The answer is 2, because the Regex engine is eager, if you use the first one, it will never give you nothing because not will always be matched first!

Figure 13: Eager
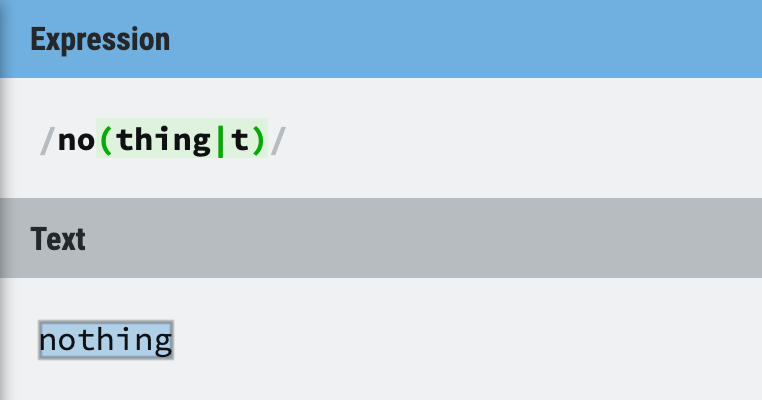
Figure 14: Eager
You can also use /nothing|not/ or /not(hing)?/ to find your matches, you can make your own choice, but for the sake of your collaborators, please choose a human-readable one!
I just saw a quote from the freecodecamp newsletter and I want to share it with you all:
“Any fool can write code that a computer can understand.
Good programmers write code that humans can understand.”
by Martin Fowler
4. Summary
Now it’s time to say goodbye, this ends my series of Regex tutorial.
I hope you have developed a solid understanding of Regex now, not only the meaning for metacharacters but also the advanced topics I’ve covered in this post.
Regex is not easy to learn, but I guarantee your effort will be paid off!
Feel free to reach me out through LinkedIn or Wechat!
Talk to Luna
Support Luna

